



Photo by Laura Chouette on Unsplash
Poetry Generator: Can we write a Sonnet like it's the middle ages?


The versatility of ChatGPT and BART has piqued the interest of many, prompting a desire to explore how these models can effectively answer an array of diverse questions. In this blog, we will introduce the process of building a basic version of a text generator. Although rudimentary, this will provide a strong foundation for future endeavors. Composing poetry is a particularly challenging task in NLP, as well as for many individuals. However, in this article, we will demonstrate how to develop a neural network model capable of generating sonnets, a type of poem famously written by Shakespeare. Our approach will involve the use of word embedding, which will be elaborated upon later in the blog.
Loading the data
You can get the data to train this poetry generator from here:
Let’s start with loading the actual data and seeing a small sample of it, say the first 300 characters.
data = open('./sonnets.txt’).read()
data[0:300]
The output of the above code block looks something like this:
FROM fairest creatures we desire increase, That thereby beauty’s rose might never die, But as the riper should by time decease, His tender heir might bear his memory: But thou, contracted to thine own bright eyes, Feed’st thy light’st flame with self-substantial fuel, Making a famine where abundance
Load the packages
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Embedding, LSTM, Dense, Dropout, Bidirectional
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import Adam
from tensorflow.keras import regularizers
import tensorflow.keras.utils as ku
import numpy as np
To check the TensorFlow version use the following code block
import tensorflow as tf
print(tf.__version__)
It should output 2.1.0
Tokenizing the training data
You can achieve this using the following code block:
tokenizer = Tokenizer()
corpus = data.lower().split(“\n”)
tokenizer.fit_on_texts(corpus)
total_words = len(tokenizer.word_index) + 1
print(‘Total number of words in corpus:’,total_words)
What this does is breaks the training data into individual lines. Then it further breaks these lines into words and assigns a unique word index to each. This is called word embedding. Moreover, counting the number of word indexes gives us the total number of unique words.
Preparing the data for training
This is the most important part of this entire script and can be broadly split into 5 steps. So let’s get into it shall we,
For each line in the text file (training data), we are going to do the following operations:
1. Converting text to sequences.
You can do that using the following:
tokenizer.texts_to_sequences([line])
Once you convert the text to sequence the output of it would look something like the following:
[34, 417, 877, 166, 213, 517]
This would be accomplished using the above-discussed unique word indexes.
2. Creating the N_gram sequences.
The next step is to create a N_gram sequence that would look something like this:
[34,417]
[34,417,877]
[34,417,877,166]
[34,417,877,166,213]
[34,417,877,166,213,517]
3. Finding the max sequence length and padding the rest.
You start by finding the length of the longest sequence and then you would pad the rest of the sequences to match that length.
NOTE: Remember to do pre-padding when doing this step.
You can do this using the following:
pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre')
The output of this would look something like this:
[0,0,0,0,34,417]
[0,0,0,34,417,877]
[0,0,34,417,877,166]
[0,34,417,877,166,213]
[34,417,877,166,213,517]
4. Creating the predictors and the labels.
This is where the most interesting part comes in, we are going to consider the last element in the N_gram sequence arrays we got above as labels and the rest of the array as the predictors. So for example:
PREDICTORS LABELS
[0,0,0,0,34] 417
[0,0,0,34,417] 877
[0,0,34,417,877] 166
[0,34,417,877,166] 213
[34,417,877,166,213] 517
The code for all of the above steps is condensed together in the next code block:
# create input sequences using list of tokens
input_sequences = []
for line in corpus:
token_list = tokenizer.texts_to_sequences([line])[0]
for i in range(1, len(token_list)):
n_gram_sequence = token_list[:i+1]
input_sequences.append(n_gram_sequence)
# get max sequence length
max_sequence_len = max([len(x) for x in input_sequences])
#pad the sequence
input_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_len, padding=’pre’))
# create predictors and label
predictors, label = input_sequences[:,:-1],input_sequences[:,-1]
label = ku.to_categorical(label, num_classes=total_words)
Defining the model
At this point, it becomes obvious what we are going to predict. The model is going to behave like a pure text classifier where the number of classes is equal to the total number of unique words and the input is the predictors defined above.
# Defining the model.
model = Sequential() model.add(Embedding(total_words,100,input_length=max_sequence_len-1))
model.add(Bidirectional(LSTM(150,return_sequences=True))) model.add(Dropout(0.18)) model.add(Bidirectional(LSTM(100))) model.add(Dense(total_words/2,activation=’relu’,kernel_regularizer=regularizers.l2(0.01))) model.add(Dense(total_words,activation=’softmax’)) model.compile(loss=’categorical_crossentropy’,optimizer = ‘adam’,metrics = [‘accuracy’])
print(model.summary())
The model defined by this would look like the following:
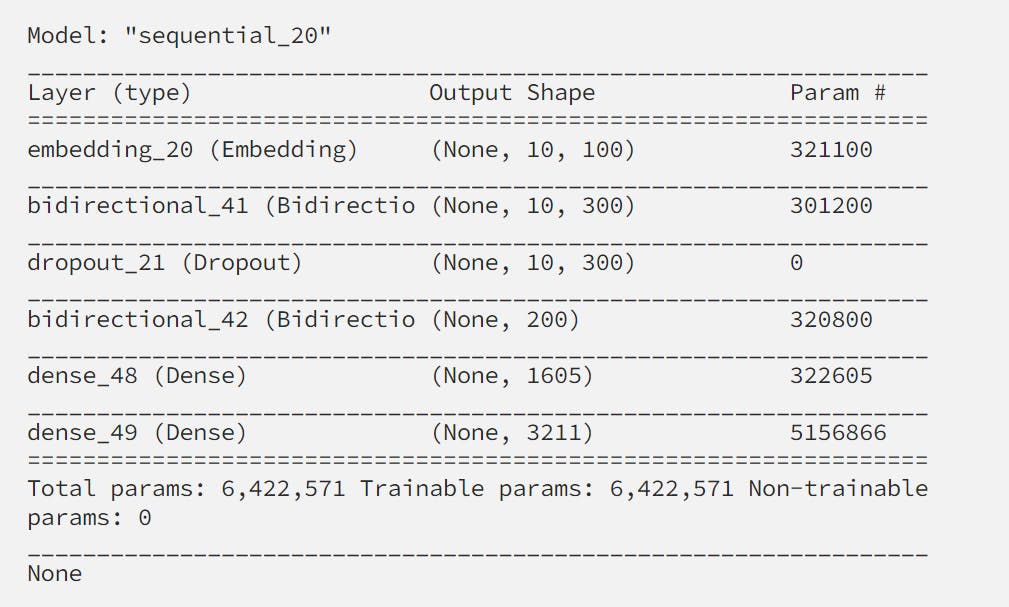
Training the model
Now to actually start training the model, this could take a couple of hours or minutes depending upon the hardware it's running on.
history = model.fit(predictors, label, epochs=100, verbose=1)

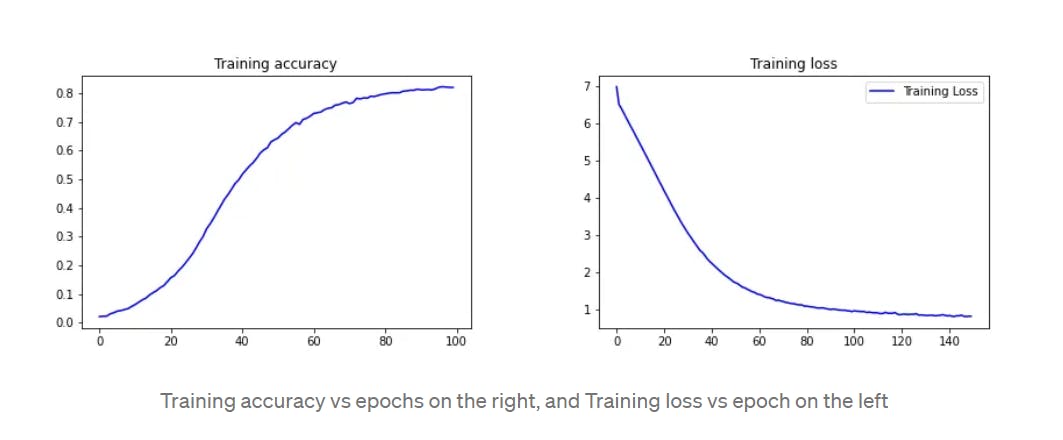
Visualizing the performance of the model
Here we are going to plot 2 graphs accuracy vs epochs and loss vs epochs.
Testing the model
To test the model we have to give 2 inputs:
Input text or seed text so the network can start predicting. and,
The number of words you want the network to predict.
NOTE: There is one major caveat to this, as the network predicts the subsequent words its loss will multiply with each new word it predicts.
seed_text = “O Ray of sunshine”
next_words = 30
for _ in range(next_words):
token_list = tokenizer.texts_to_sequences([seed_text])[0]
token_list = pad_sequences([token_list], maxlen=max_sequence_len- 1, padding=’pre’)
predicted = model.predict_classes(token_list, verbose=0)
output_word = “”
for word, index in tokenizer.word_index.items():
if index == predicted:
output_word = word
break
seed_text += “ “ + output_word
print(seed_text)
The Poem our network so created is as follows:
O Ray of sunshine
this sin what in thee array grows
so lie new die dearer their strong hide
prove thee seen their chest be gay
commence account it cheeks worth new one strong
Before You Leave
The corresponding source code can be found here.
https://github.com/PraveenKumarSridhar/poetry-generator
Thank you for reading this, hope you found it interesting.
PS this is my first post, so any comments on how to Improve are more than welcome.